
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | ||||
| 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| 11 | 12 | 13 | 14 | 15 | 16 | 17 |
| 18 | 19 | 20 | 21 | 22 | 23 | 24 |
| 25 | 26 | 27 | 28 | 29 | 30 | 31 |
- 오류검출
- 서비스 프리미티브
- 오블완
- 오류제어
- 플로이드워셜
- 프레임 구조
- 토큰 버스
- 스레드
- 항해99
- 99클럽
- 주기신호
- 티스토리챌린지
- mariadb
- well known 포트
- 개발자취업
- 순서번호
- tcp 세그먼트
- leetcode
- 코딩테스트준비
- xv6
- reducible
- git merge
- i-type
- tcp 프로토콜
- 우분투db
- til
- IEEE 802
- 데이터 전송
- 그리디 알고리즘
- 비주기신호
- Today
- Total
Unfazed❗️🎯
ch2_learning2 (Balancing Flexibility to Optimize Model Accuracy) 모델의 정확도 평가 본문
ch2_learning2 (Balancing Flexibility to Optimize Model Accuracy) 모델의 정확도 평가
9taetae9 2024. 3. 13. 20:18Assessing Model Accuracy
So many machine learning methods!
• A single best method for all data sets? Nope!
• One method may work best on a particular data set.
• But, some other method may work better on a similar but different data set
How to compare Methods?
• Given a set of data, which method will produce the best result?
• In other words, how to compare different learning methods?
Measuring quality of fit
• Evaluate the performance of a statistical learning method on a given data set
• For regression problem, a common measure of prediction accuracy is the
mean squared error:
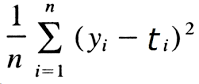
• We choose the model that achieves smallest MSE.
training MSE vs. test MSE
• training MSE: easy to minimize
• but, training MSE ≠ test MSE
• test MSE is what we really want to minimize!
Overfitting
• “working too hard” to find a pattern from irreducible error!
Y = f(X) + e

test MSE
training MSE
왼쪽 그래프에서 검은색 선은 실제 함수 f 를 나타내며, 이는 우리가 추정하고자 하는 실제 데이터의 분포를 의미한다. 여기에 주어진 데이터(동그라미로 표시된)는 실제 함수에서 발생했다고 가정한다. 오렌지색 선은 선형 회귀 모델을 통해 얻어진 추정치를 나타냅니다. 선형 모델은 데이터의 전반적인 경향성은 파악하지만, 데이터의 모든 패턴을 잡아내지는 못한다. 파란색과 녹색 선은 각각 더 많은 유연성을 가진 모델을 통해 추정된 값으로, 이러한 스플라인 혹은 비선형 모델은 데이터의 지역적인 변동성을 더 잘 포착한다.
오른쪽 그래프는 유연성에 따른 평균 제곱 오차(Mean Squared Error, MSE)를 보여준다. 여기서 유연성은 모델이 데이터에 얼마나 잘 맞추는지의 정도를 의미합니다. 회색 선은 훈련 MSE를, 빨간색 선은 테스트 MSE를 나타낸다. 일반적으로 훈련 MSE는 모델이 더 유연해질수록 낮아지는 경향이 있지만, 테스트 MSE는 일정 포인트 이후에 증가하기 시작한다. 이는 모델이 너무 유연해져서 훈련 데이터에 과적합되어 실제 새로운 데이터에 대해서는 잘 작동하지 않음을 의미한다. 이상적으로는 테스트 MSE가 최소인 모델을 찾으려고 한다. 그래프의 사각형은 각 추정치(오렌지, 파란색, 녹색)의 훈련과 테스트 MSE를 나타낸다.
Q. Which captures the data best? => green (training mse 가장 낮음)
The green curve best captures the training data as it fits closest to the individual data points, following the fluctuations in the training data with the highest precision. This level of flexibility in the model tends to demonstrate a high degree of fit to the given data. However, it's important to be cautious of the potential for overfitting when applying the model to test data.
주어진 훈련 데이터를 가장 잘 포착하는 것은 녹색 선이다. 데이터 포인트에 가장 근접하게 맞추어져 있고, 훈련 데이터의 변동성을 가장 세밀하게 따라가고 있는 것을 볼 수 있다. 이러한 고도로 유연한 모델은 주어진 데이터에 대해 높은 적합도를 보이는 경향이 있다. 그러나 테스트 데이터에서는 과적합(overfitting)이 발생할 수 있음을 유의해야 한다.
Q. Which is the best estimate of f? => blue (test mse 가장 낮음)
The blue model is considered the best estimate of the true function f, as it captures the structure of the data effectively while avoiding overfitting, thereby demonstrating the greatest generalization ability on new data. This is evidenced by its lowest test MSE, indicating a balance between fitting the training data and maintaining predictive performance on unseen data.
파란색 모델이 데이터의 구조를 잘 포착하면서도 과적합되지 않아 새로운 데이터에 대한 일반화 능력이 가장 뛰어나다.
데이터를 가장 잘 포착하는 모델과 f의 최선의 추정치에 대해 알아보자. 오렌지색 모델은 데이터의 전반적인 추세를 잘 파악하지만, 모든 패턴을 잡아내지는 못한다. 파란색과 녹색 모델은 데이터의 세부적인 변동까지 잘 포착하고 있지만, 너무 유연해서 테스트 MSE가 증가하는 과적합의 위험이 있다. 그래프 상에서는 파란색 모델이 테스트 MSE가 가장 낮기 때문에, 일반화 측면에서는 파란색 모델이 f의 최선의 추정치로 볼 수 있다.
In general,
• more flexible a method ➔ lower training MSE
• However, the test MSE may be higher for a more flexible method!
Avoid overfitting!
Choose just the right level of flexibility to avoid overfitting in mind!
'AI > 머신러닝' 카테고리의 다른 글
| ch2_learning2 편향-분산 Bias-variance Trade-off (0) | 2024.04.16 |
|---|---|
| Comparative Analysis of Classification Models: Logistic Regression, Naive Bayes, LDA, and QDA (0) | 2024.04.03 |
| ch2_learning (0) | 2024.03.12 |
| ch1_overview (0) | 2024.03.06 |
| Multi-Layered Perceptron (MLP) : Structure (0) | 2023.10.16 |
